
短いようで長く濃密な時間だった。
ふと振り返ると、もう10歳くらいは歳をとったのではないかと思う。それくらい、毎日が充実しているし、時間が流れるのを遅く感じる。
白状すれば、最初の頃は、「ニューラルネットの学習方法をちょっと工夫するだけで、本当にそんなにうまくいくものか」と懐疑的だった。しかし次第にディープラーニングの輪郭がハッキリしてきた時、僕は自分がそれまで漠然と考えていた「知能」というものに対する考え方そのものを変える必要がある、という啓示にも似た衝撃を受けた。
たいがいの大学の先生は眉をひそめる表現になるが、誤解を恐れずに言えば、僕はディープラーニングが獲得した能力を「直感」だと考えている。「ピンと来る能力」と言い換えてもいい。
たとえば、犬と猫を知らない子供に犬か猫の写真を見せて、電話で「こういう特徴があったら、それは犬であり、こういう特徴があったら、それは猫である」と説明することを想像して見てほしい。
おそらく言葉では説明できないはずだ。
犬も猫も毛がふさふさしており、鼻は黒く、耳は尖ったり垂れ下がったりしている。
しかし人間ならば、たとえ本物の犬や猫をみたことがなくとも、「これは犬である」「これは猫である」と視覚で示せば一発で理解できる。ここではこれを「直感」と呼ぶとしよう。
ディープラーニングを使う人工知能にも同じことが言える。ひたすら犬と猫を見せて、気がつくとなんとなく「犬っぽさ」と「猫っぽさ」を把握できるようにAIの「直感」が磨かれるのだ。
僕がディープラーニングの成果に関して、「いよいよこれは直感に近くなってきたな」と感じたのがGoogle傘下のDeepMindが発表したDQN(Deep Q-Network)である。

有名なブロック崩しを攻略するデモ動画に心底興奮したことを覚えている。
もっと驚くべきことはその構造だ。
DQNの構造は、ピーター・ダヤンらが1992年に発表したQ学習(およびその内部構造に持つQ関数)と、ディープラーニングの畳み込み層を単純につなげただけのものである。
この時点で、DeepMindが独自に発明したものは実はなにもない。古典的な手法にモダンな手法を組み合わせただけだ。
DQNについては、DeepMindは手法の発明者というよりも、組み合わせの発見者であったと言える。
その後、DeepMindはAlphaGoを作り、ついには最難関ゲームと言われた囲碁の攻略に成功する。
それどころか、AlphaGoのアルゴリズムをベースに作られたAlphaGo Zero、そしてその汎用バージョンであるAlphaZeroは、将棋、オセロ、囲碁、チェスを含む全ての決定論的ゲームの攻略を実現した。
AlphaZeroもまた、古典的なモンテカルロ木探索(MCTS)という手法に畳み込みニューラルネットを組み合わせただけの構造であったので、再現実験が容易だった。
その結果わかったのは、AlphaZeroのアプローチでは、確かに「学習を続けていけばいつの日か最強になる」ことはどうも間違いないが、ほぼ無限大に近いほど広い選択肢がある場合、天文学的な計算機か、天文学的な時間が必要ということだ。
なぜならAlphaZeroは人間と違い、初期値の出来不出来に左右される。
あくまでもランダム探索をするだけなので、あたり(必勝)を引くためには信じられないくらい多くの場面を経験させなければならない。
AlphaZeroの原理を極めて単純に説明すれば、ある盤面をAIが「見た」とき、どんな「手」を打つと、ゲームの終了時には勝っていたのか、それとも負けたのか、ただひたすら「この盤面でこの手は、ありかなしか」を学習するだけだ。
だからやはり僕の感覚ではこれは人間でいう「勝負勘」という直感に近い。人間は、いくら理詰めで考えているように見えても、頭の中で、最後は直感に頼るのだ。だから囲碁や将棋の真剣勝負が成り立つ。
僕は、AlphaZeroが、あれほど複雑な囲碁のようなゲームが攻略できるのだから、当然、もっと情報量の少ないポーカーや麻雀のようなゲームでもできるに違いないと独自にAlphaZeroを改造し、実験を続けた。
ところがこれがなかなかうまくいかない。3日学習したポーカーAIと、30日学習したポーカーAIでは、明らかに後者のほうが強いのだが、人間と戦うと人間のほうが勝ってしまうことがしばしばあるのである。
というよりも、実際にAIが打った手筋を見ると、たとえばAのスリーカードができているのに、それをあえて崩してフルハウスを狙ったりとか、明らかに無謀な手を試しているのだ。
囲碁の場合の盤面のパターンを数えてみよう。マス目の数は19x19=361であり、ここに白黒ナシの三状態があるから、3の361乗で1.7×10の172乗パターン。
ポーカーの場合、手札はたった5枚しかないので、捨て札をあわせると取りうるマス目の数はたかだか1プレイヤーあたり10個くらいと一見シンプルだが、一枚ずつ交互にカードを引くルールで、一回の交換と仮定しても、最大五枚交換できるので最大20個の順列組み合わせになり、52P20=3溝0653穣2583柹2231垓0954京3994兆3000億0640万パターン。数学的には、初期状態を全て順列組み合わせで考える必要はないなど細かいツッコミはあるだろうが、ここでは敢えて無視する。
しかも、囲碁の場合は、ある盤面に対する打ち手に対する「勝ち/負け」はひとつだけである(決定論)が、確率論的ゲームのポーカーの場合はたとえ全く同じ盤面、同じ打ち手であっても、勝つ場合もあれば負ける場合もある(確率論)ので、実際にはもっと膨大なパターン数となる。
細かい計算は省くが、ポーカーにおける全ての局面のパターンを試すのに、ひとつの初期状態からゲーム終了までだいたい1秒で終わるとして(これはかなり高速に計算をしたほうだ)も、宇宙が生まれてから現在までの時間を約647兆回繰り返してようやく全ての盤面を網羅できることになる計算だ。
むしろ3日と30日の学習における差など誤差の範疇であって、これで人間に勝てるとしたらまぐれとしか言いようがない。たかがポーカーといえどそうなのだ。麻雀ともなればさらに複雑さは増す。
一般の人が人工知能に対して抱く期待の多くが、実際には「囲碁で人類を凌駕した」ということに象徴されるような、「特殊な高知能」であるとすると、実は初期状態が同一の決定論的ゲーム(つまり囲碁、将棋、オセロなどである)しか解けないのだとすると、人工知能というやつは現実には何の役にも立たないということになってしまう。そんな特殊な状況はそうそう発生しないからだ。
現実の問題というのは、初期状態が同じことなどまず存在せず、そもそも現在状態からして確率論的にしか把握できないのが当然である。
そのような状態でも、正しい判断ができることを人工知能が求められるのだとすれば、初期状態が完全なランダムに近い状態であっても、確実な状況判断を行なう人工知能開発こそが世の中で求められるものだろう。
そこで僕はいちど強化学習の原点を振り返ることにした。
そもそも深層強化学習の最も知られた例であるDQNを構成する重要要素のうち、D(Deep)については僕はもういっぱしの専門家である。ニューラルネットワークの実装に関しても、足掛け30年の経験がある。では、「QN(Q-Network)」についてはどうだろう。実はQ学習を含む「強化学習」という概念は90年代初期のもので、ニューラルネットそのものとは直接関係のなかった考え方だ。
では今、Q学習や強化学習を考えた人たちというのはどこにいるのだろうか。
そこで唐突に、我が社(ギリア)発祥のもとになり、僕自身が学生時代に最も影響を受けた論文である北野論文の一説を思い出した。北野宏明が1990年代に掲げた目標により、「西暦2050年までに、人間のサッカーの世界チャンピオンチームに勝てる、自律型の人型ロボットチームを作る」ために、1997年から現在に至るまで、約20年にわたって行われている世界的ロボットコンテストがある。RoboCupだ。
「そういえば最近のRoboCupはどうなっているのだろうか」
最近のRoboCupの動向について少し調べてから驚愕した。20年前と上位チームがほとんど変わっていないからだ。MITやソルボンヌはもちろん、スタンフォード、カルテック、あらゆる一流大学のチームを下し、20年にわたるRoboCupの歴史の中で、10回もの優勝を納めた圧倒的名門チームが存在する。Peter Stone教授率いる、テキサス大学オースティン校のチーム UTAustin Villaだ。
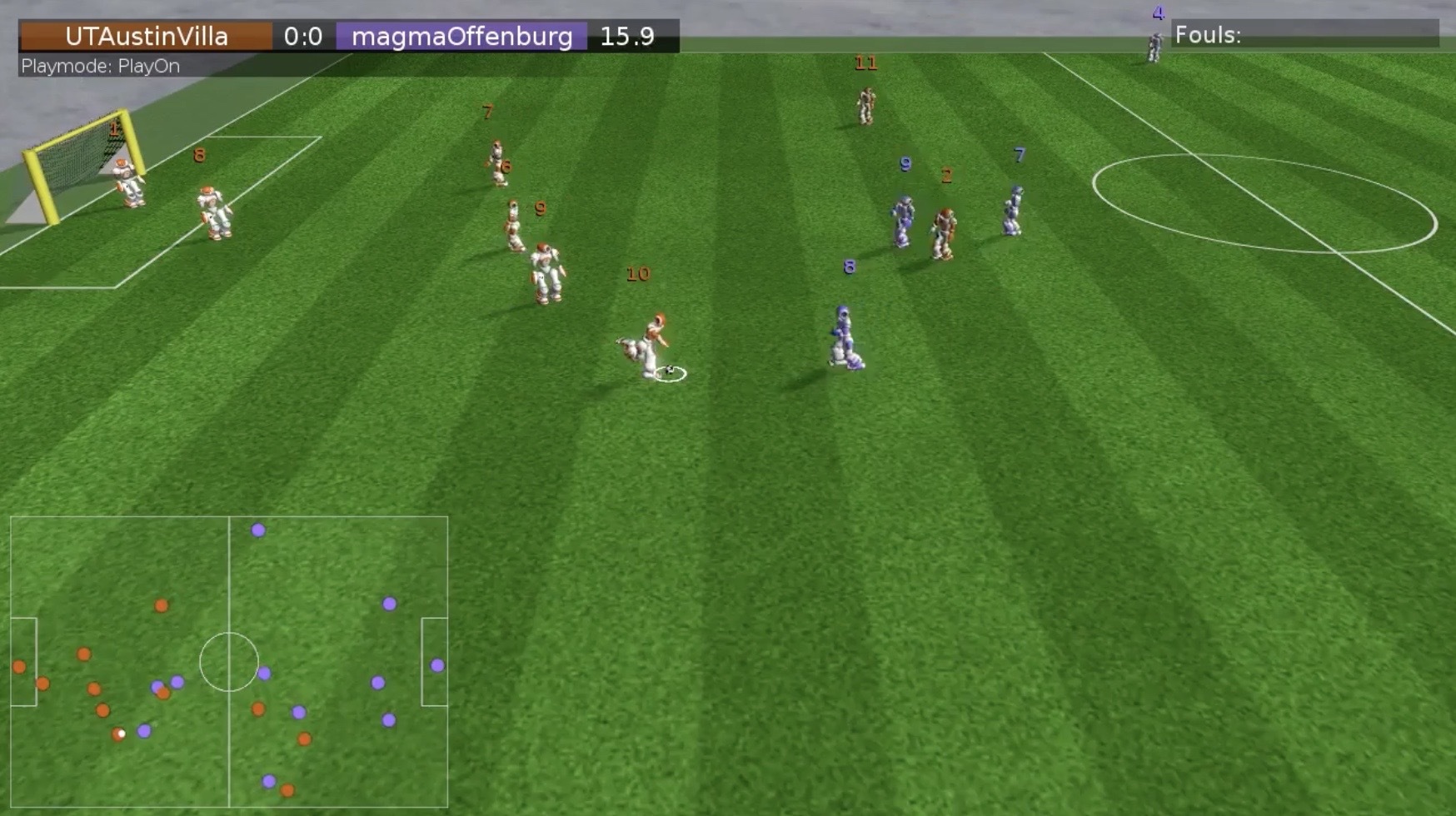
決勝のビデオ(https://www.youtube.com/watch?v=3EKYH38QYxo)を見ると、かなり高度なプレイをものにしていることに改めて驚く。
解説によれば、これらは全て機械学習によって自律的に学習・獲得されたアルゴリズムによる動きだという。
RoboCupのルールではシミュレーションリーグといえど全てのロボットは自律動作させなければならないので、不完全かつ確率的な事象を扱いながら、ここまで複雑なコンビネーションプレイを実際に強化学習だけで獲得できるというのはにわかに信じることができなかった。まさしく次元の違う強さだ。
これはすごい、と思い、さっそくアポをとった僕はテキサスへ向かった。

真夏のテキサスは予想通りの暑さで、陽光に目を細めながら、University of Texusのキャンパスをさまよった。
なにしろただでさえ広いアメリカの、ただでさえ広いテキサスの、ただでさえ全米屈指の生徒数を誇るテキサス大学のキャンパスときたら、車なしでは移動できないほどだ。
ようやくたどり着いた研究室のボスはピーター・ストーン教授。UTAustin Villaのリーダーであり、強化学習の第一人者だ。

ピーターは三年前から強化学習を専門とする学者チーム16人を集めた法人研究組織「Cogitai(コジタイ)」社をまとめる社長であり、Cogitaiには二年前ソニーも出資している。
運良くそんな縁もあってアポイントメントもとりやすかったのだが、このCogitai社に参加している学者というのがまた半端ない。
学者のひとつの価値というのは、論文の引用数で決まる部分がある。先行研究には敬意を評しなければならないというのが研究者コミュニティの常識であり、新しい分野を切り開いて影響力が大きいほど論文の引用数というのは多くなる傾向が高い。
ピーター・ストーン教授自身も論文引用数2万以上というレジェンド級の学者だが、他にも論文引用数3万を超えるCTOのバベジャ教授(ミシガン大学)や、なにより、Q学習そのものの発明者、ピーター・ダヤン教授(ロンドン大学)、デビッド・パークス教授(ハーバード大学)など、そうそうたる顔ぶれである。

これがテキサス大学が誇る、世界最強の人型ロボットサッカーチームである。 まずは3D物理シミュレーション環境で走り方やキックの仕方を練習し、パス回しなどを練習したあとで現実世界のロボットに転送し、現実世界のロボットの動きとシミュレーションの差分からシミュレーションの方を現実にあわせて修正する、いわゆるスパイラル学習を数年前から導入しているという。
特に近年の彼らの中心課題は、単なる強化学習ではなく、「継続的学習(continual-learning)」にある。
実は強化学習というのは、プログラムを実際にしてみればわかるが、実際にはかなり即物的かつ強引な学習方法である。
「この場面でこういう手を打った時は勝った」「このときは負けた」ということを幾度も、それこそ何億回、何兆回と繰り返すに過ぎない。
しかしそれは、あくまでも「どこかの時点でゲームに勝ち/負け/引き分け」といった終わりがあるという前提がなければならない。
強化学習が「終わりのあるゲームにおける状況判断の学習」だとすれば、継続的学習とは、「終わりのない戦いにおける状況判断の学習」についての手法である。
Google傘下のDeepMindがDQNを発表して以来、ディープラーニング界隈でもにわかに強化学習ブームが巻き起こった。DeepMind自身が開発したA3Cなどの最新のモデルもあるが、いまのところ「どんなゲームでも攻略できる」とは到底言えないというのが現状だ。
それに対して、日本ではほとんど話題になっていないが、今年の1月にピーター・ストーン教授らのチームが発表した新たな学習手法、「Deep TAMER」は非常に画期的なものだった。

Tamer(テーマー)とは、「調教師」のことである。
DeepTAMERでは、AIのエージェント(agent)がゲーム環境(environment)で遊ぶのを人間のTamerが観察するというところがミソだ。
人間は、コンピュータの振る舞いに対し、適宜「いまのプレイは良い」「いまのプレイはダメ」ということをヒントとして教えてあげるだけで良い。
ようは、AIを人間がコーチするのである。
ただそれだけのことで、これまでに発明されたどのような強化学習アルゴリズムよりも早く効率的に学習することができる。

上図はGoogleが開発したA3CとDouble-DQNとDeepTAMERとの比較だが、全くスコアが上がっていかない他の手法に対して、Deep TAMERが圧倒的な差で短期間に高スコアを達成していることがわかる。
面白いのは、わずか6分の学習で人間のテーマー(調教師)のスコア(Human Trainer)を塗り替え、さらに10分後には人間の熟練者(Expert Human)のスコアさえも凌駕しているところだ。
そしてここに僕は世界最強のAIを開発する大きなヒント、いや、ほとんど答えがある、と見出したのだ。
「最強」とは何か。「一番強い」ということである。
これまで、「世界最強のAI」を作るには、「世界最大の計算資源」が必要だった。なぜならば、膨大なパターンの盤面をランダム探索するという方法によってしか最強の人工知能を作ることができなかったからだ。
しかし「世界最大の計算資源」をもってしても、ポーカーのように初期状態が膨大なパターンあるような不確定性を含む問題を解くことはできなかった。要は探索すべき目標パターンが膨大なのである。想像を絶する数である。
ところがここに人間のコーチが指導することによって、一見膨大に見えるパターンを一気に絞り込むことができる可能性が見えてきた。「世界最大の計算資源」は、こと確率論的ゲームにおいては人間の勘に劣る場合があるのだ。
そこには力技とは真逆の、勝利への美学、人間本来の勝負勘、強さ、というものがある。
そしてこれは「ゲームが変わればコーチとなる人間も変える必要がある」という一見するとあたりまえの結論に結びつく。
僕自身、ゲームデザイナーでありプログラマーでもある立場から言わせてもらえば、「ゲーム」とは数理モデル化可能な現象全てを意味する。すなわち、経営、マーケティング、広告、人事、物流、エトセトラ、エトセトラ、「戦略」という言葉がつくもの全ては「ゲーム」であると言える。
ということは、この「ゲーム」の定義によっては地域性も大きく関係してくるだろうし、文化的背景も色濃く影響することになる。
人間の洞察力と継続的に学習可能な人工知能が組み合わさった時、それは人知を超えた超知性に限りなく近づくことになるわけだ。
ピーターと意気投合した僕は、その場で戦略的パートナーシップを提案し、それはほとんど即決で決定された。細かな調整のため、発表は数ヶ月遅れて今週になってしまったが、すでに複数の案件で動き始めている。
実はCogitai社は、自社の技術をどう社会に適応させていけば良いか、というところで悩みを抱えていた。
なんせ主要メンバーが超一流の大学教授を兼務している。彼らには世界一の技術はあるが、ビジネスにつなげるところは弱い。
どんな人工知能もーーとりわけコーチが必要な人工知能はそうであるがーー、ビジネスの現場と結びつかなければ絵に描いた餅に過ぎない。
幸い、我が社(ギリア)は、強力な株主たちのバックアップもあって、日本の主要な産業のプレイヤーの「ビジネスの現場」にどのような課題があり、どのような解決策を求められているか、ということに関して熟知している。
ビジネス的な接点はもちろん、現実の課題をどのように数理モデル化(ゲーム化)するかということは我々の得意分野である。
世界規模の研究チームの力を得て、我々がどのように世界最強AIへの道をひた走っていくか。どうかご期待されたい。
{kind=link}
コメント
コメントを投稿